Через неделю, в следующий вторник, 7 апреля, состоится большая конференция (плавно переходящая в симпозиум*;) NetApp Innovation 2009.
На сегодня , наиболее важные и интересные доклады которой я позволю себе здесь, для привлечения внимания, опубликовать:
NetApp Delivers Breakthrough Innovation for Oracle’s Global Consolidation
Hear how Oracle Global IT saved $1 Billion in 2 years by consolidating, standardizing, automating and choosing strategic partners like NetApp. By leveraging technologies such as thin provisioning, virtual cloning and space automation, Oracle is achieving storage utilization rates more than twice the industry average.
Jack Rogers. Director - Oracle On Demand Architecture Зарубежный опыт. Успешное многолетнее использование Ораклом систем NetApp для своих нужд.
Применение технологий NetApp в ВТБ
Сергей Удалов, Зам. начальника Управления внедрения и сопровождения информационных систем ВТБ О практической реализации, редкий в наших краях пример публикации Success Stories большого внедрения в известной компании.
Архивирование как шаг к эффективному хранению данных
Роман Прытков, ведущий технический консультант Symantec. Взаимодействие с продуктами Symantec, полагаю, что про Enterprise Vault будет сказано.
VMware Infrastructure - платформа для построения ЦОД нового поколения
Дмитрий Тихович, ведущий консультант VMware.
Совместные решения Brocade и NetApp на платформе 8 Гбит FC
Павел Добринский, системный инженер, Brocade
FlexFrame for SAP: динамическая IT-инфраструктура для бизнес-приложений
Николай Гришин, Эксперт по решениям для SAP Fujitsu Уже не новинка, но по прежнему недооцененная технология.
Демонстрация - использование технологий мгновенного копирования, дедубликации и клонирования на примере VMware.
Ян Александровский и Сергей Ким, Эксперты i-Teco Всегда зрелищная и популярная тема.
PAM как закись азота для систем хранения
Роман Ройфман, архитектор решений NetApp Performance Acceleration Module. Новинка и уникальная технология с большим будущим.
Особенности NFSv4 и перспективы развития. Дискуссия
??горь Увкин, технический директор NetApp
13:00 - 14:00 Обед :)
* симпозиум (гр., т.ж. “симпозий” ) - совместный обед с выпивкой и разговорами у греческих философов.
На днях также обнаружил, что такой популярный сервис хранения фотографий как Flickr (я и сам им пользуюсь), также хранит свои данные на системах хранения NetApp.
Что, в общем неудивительно, так как Flickr вот уже несколько лет входит в Yahoo!, а Яху, как известно, крупнейший в мире (по объемам хранения) клиент NetApp.
?? даже более того, после ухода Джерри Янга с поста CEO, его заняла Кэрол Берц, в прошлом также один из руководителей NetApp.
??нтересная статья о архитектуре Flickr была найдена на сайте , кстати и вообще это любопытное место, если вы интересуетесь принципами построения высоконагруженных решений.
По состоянию на конец 2007 года:
Более четырех миллиардов запросов в день
Примерно 35 миллионов фотографий в дисковом кэше Squid
Около двух миллионов фотографий в оперативной памяти Squid
Всего приблизительно 470 миллионов изображений, каждое представлено в 4 или 5 размерах
38 тысяч запросов к memcached (12 миллионов объектов) в секунду
2 петабайта дискового пространства
Более 400000 фотографий добавляются ежедневно
К сожалению, никаких подробностей о том, что именно используется, пока не обнаружено. “Сервера хранения NetApp”. Ну и правильно, включили - работает, чего обсуждать. “сало як сало” ;) Как это похоже на NetApp…
Десять лет жили себе, не тужили без него, и вот на тебе, счастье на нашу голову. Зачем нам этот RAID новый, или старых не хватает?
Получается что не хватает, и давайте смотреть чего именно.
Во-первых, почему о RAID-6, или “RAID c двойной четностью” заговорили именно сейчас?
Причина - в резком, и продолжающемся росте емкости единичного жесткого диска.
Количество байт на устройство становится все больше, а вероятность сбоя чтения, исчисляемая в случаях на количество прочитанных-записанных байт, остается практически неизменной. Я сейчас говорю не столько о надежности самого диска вида “сломался”, сколько о надежности математики чтения с поверхности дисков.
Допустим, что мы предполагаем (условно) вероятность сбоя чтения одного бита из ста миллиардов. Но это только кажущаяся большая цифра и низкая вероятность, так как она означает, что мы будем получать ошибку чтения примерно каждые 12 с половиной гигабайт прочитанной информации. Конечно, реальная вероятность сбоя значительно, на много порядков ниже, но она, тем не менее, не нулевая. Официальную величину можно найти в данных на тот или иной тип дисков у производителя.
То есть если раньше один случай вероятного сбоя вида “неверно прочлось и не исправилось математикой контроллера, oops…” был распределен на объем прочитанных байт, расположенных, например, на десятке дисков, то теперь, когда емкость одного диска увеличилась, количество дисков, несущих этот же объем байт, резко сократилось. ?? теперь вероятность сбоя дисковой группы резко выросла. Ведь теперь сбой возможен на гораздо меньшем количестве дисков. Допустим раньше у нас был массив в 4TB из 30 дисков 144GB. Создав на нем 6 групп RAID-5 4+1 мы получаем, что мы готовы перенести, без потери данных, до 6 сбоев диска, по одному в каждой RAID-группе.
Но времена меняются, и теперь 4TB это всего 5 дисков вида RAID-5 4+1. А вероятность в, условно допустим, 6 сбоев на такой объем осталась прежней.
Это значит, что на больших массивах, RAID-5, защищающий от единичного сбоя, больше не защищает ни от чего.
Это значит, что в случае дискового сбоя, на время ребилда RAID, а это время на дисках 146GB под нагрузкой занимает до суток, а на дисках большего размера, соответственно, больше, сообщают о величинах до 80-100 часов.
Готовы ли вы примерно на четверо суток оказаться без RAID для ваших данных вообще?
“Без RAID” (RAID-0, другими словами) потому что на время ребилда любой сбой чтения-записи, на любом диске, приведет к потере данных теперь уже гарантировано.
Конечно картинку я рисую несколько утрированно апокалиптическую, но тенденция именно такова, и игнорировать ее уже нельзя.
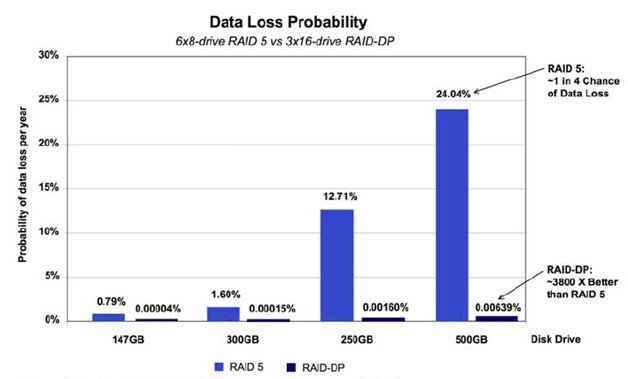
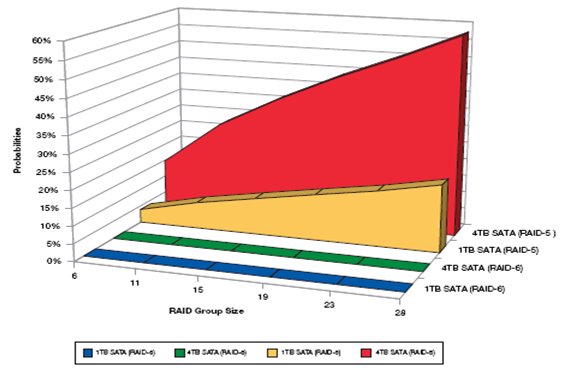
Показательная иллюстрация была найдена в документации NetApp.
А это - данные HDS (чтобы вы не думали, что это все пропаганда в пользу одного вендора).
Отчасти задача, казалось бы, решается с помощью RAID-10 (RAID 0+1). При благоприятном стечении обстоятельств мы можем пережить отказ в половине дисков, однако, если эти диски из разных “половин” зеркала. Однако, как заметил еще Мерфи, обстоятельства склонны случаться в наихудшем из возможных вариантов.
??менно рост объемов на один диск, и, как следствие, повышающаяся вероятность сбоя “на шпиндель хранения”, вызвало тот факт, что сегодня практически все вендоры предложили в своих системах хранения реализации “RAID с двойной четностью”.
Ну хорошо, скажете вы. Отчего мы тогда все не применяем RAID-6 повсеместно?
Увы, один, но значительный минус присутствует. Будучи сравнимой в показателях производительности при Random Read, Sequential Read и Sequential Write, RAID-группа с типом 6 как правило сильно проигрывает (практически на треть!) на Random Write, что практически лишает RAID-6 шансов на использование в задачах, критичных к быстродействию по тому параметру, например OLTP-базы данных, и подобных им. Более того, практически, применения RAID-6 в его классическом виде, возможно только на весьма ограниченном пространстве задач, таких, как, например бэкапы, или DSS-базы, то есть задачи без Random Write. По крайней мере Best Practices вендоров тут единодушны.
На фоне этих невеселых сведений особняком стоит реализация “RAID с двойной четностью” от NetApp - RAID-DP.
Будучи собственной, независимой реализацией RAID-6, полностью соответствующей определению RAID-6, данном SNIA, она принципиально отличается от собственно RAID-6 тем, что показатели на Random Write на такой дисковой группе не ухудшаются, как это характерно для “классического” RAID-6. Если совсем буквоедствовать, то ухудшение присутствует, но в пределах нескольких процентов, против примерно 20-33% у “классического RAID-6″.
Это единственная такая реализация RAID-6 из существующих на рынке.
Это позволило рекомендовать NetApp использовать RAID-DP как тип “по умолчанию” для всех своих систем хранения.
Больший же расход дисков на “погонный usable гигабайт” компенсируется тем, что в случае использования RAID-DP мы можем использовать более длинные RAID-группы, без опаски за надежность хранимых данных. Так, например, если ранее, с RAID-4 NetApp рекомендовал использовать группы по 7+1 дисков, то в случае RAID-DP рекомендации говорят о 14+2-дисковых группах (а максимально возможно 28!), как можно видеть, количество дисков, которые мы отдаем за обеспечение отказоустойчивости не увеличивается, а надежность растет, как мы показали ранее.
Dave Hitz:
С обычным RAID, мы рекомендуем пользователям создавать массивы RAID из 7 дисков плюс 1 parity disk. При использовании RAID-DP, мы рекомендуем создавать массив из 14 дисков, плюс 2 parity disks. Таким образом, это 2 parity disks на каждую полку с 14 дисками. При этом математика говорит, что RAID-DP на 14 дисках много, много безопаснее, чем обычный RAID на 7 дисках.
Как обещал ранее, даю ссылку на переведенный документ по внутреннему устройству WAFL (Write Anywhere File System). Оригинал был опубликован в конце 1994 года в журнале USENIX, и, по сути, это то, с чего NetApp начался как идея, и как компания.
В основе всех устройств NetApp (ну разве кроме систем потокового шифрования Decru, и Virtual Tape Libraries (VTL) относительно недавно купленных ими) лежит эта “файловая система”, хотя правильнее было бы называть ее “файловая структура”, file layout.
Чем по сути отличается File System от File Layout, почему эта разница так важна, как так получилось, что система, задуманная изначально как файловый сервер (NAS) без особых затруднений вскоре стала работать и как блочное SAN-устройство - об этом вы узнаете в нашей следующей серии :)
Менее чем через месяц, 7 апреля, пройдет главное нетапповское мероприятие года, конференция NetApp Innovation. Хотя на сегодня подробная программа и не определена еще, но интересующимся темой рекомендую не пропускать.
Скорее всего ведущими темами будут системы серверной виртуализации, и все с ними связанное, такое как “Программа гарантий NetApp”, о которой я писал ранее, дедупликация на системах хранения, thin provisioning, и прочие средства хранить информацию эффективно.
Ну и, наконец, это отличное место потерзать инженеров российского NetApp вопросами, и получить ответы “из первых уст”.
Будете в Москве - заходите :)
Вчера мы разбирали вопрос “существует ли фрагментация данных на дисках систем хранения NetApp”, и пришли к выводу, что проблема эта чересчур драматизируется теми, кому положено ее драматизировать нашими уважаемыми конкурентами.
Однако пытливый читатель спросит меня: “Так все же, “сколько вешать в граммах?”
Вопрос: А как понять величину фрагментированности? Это много, или мало? А если много, то что делать? ?? насколько оно влияет, если много?
Ответ: Давайте разберем по порядку.
В документации, в разделе, посвященном команде reallocate говорится: reallocate measure [-l logfile] [-t threshold] [-i inter_val] [-o] pathname | /vol/volname
Запуск измерения реаллокации для LUN, больших файлов или томов.
threshold - порог, ниже которого LUN, файл или том считаются неоптимизированными (фрагментированными) достаточно, для того, чтобы запустилась реаллокация, величина от 3 (средне оптимизирован) до 10 (очень сильно неоптимизирован). Значение порога по умолчанию равно 4.
??так, если вы настроили reallocate на работу по расписанию, то он стартует в назначенное вами время, с необходимой вам периодичностью, и, если обнаруживает на дисках фрагментацию выше заданого порога, начинает ее уменьшать, работая фоновым процессом с минимальным приоритетом, по отношению к задачам собственно системы хранения.
Но пока непонятно что же стоит за этой величиной, какой “физический смысл”?
Хочу еще раз привлечь внимание админов NetApp к существованию на большой подборки техдокументации. NOW сегодня не такой плюшевый как, например, MSDN, но пользоваться можно.
“Еще раз”, потому что знаю, что многие админы, пользуясь тем, что системы NetApp на самом деле очень просты в эксплуатации, “настроил раз, за 15 минут, и они работают”, мало внимания уделяют копанию в документации, особенно англоязычной. А зря. В ней много интересного.
Вот, например, What do the the WAFL scan measure_layout ratio and measure_layout numbers mean?
“Что означают цифры measure_layout ratio и measure_layout при выполнении операции WAFL scan?”
Для Data ONTAP versions 6.5 и позднее
measure_layout ratio: Это отношение между числом записанных “чанков” (”chunks”, “кусков”) которые занял файл, и теоретическим минимумом числа таких чанков, которые были бы записаны для этой операции на полностью пустой файловой системе. Если ей ничто не помешает, то WAFL запишет данные в последовательные чанки размером 256 KB на каждый диск тома. Но если система не найдет куска последовательных 256 KB свободного места, то она запишет кусок меньшего размера.
measure_layout считает число чанков, в которые попали данные, и делит это число на их минимально необходимое количество. Таким образом наилучший возможный результат равен 1 (число записанных чанков равно числу минимально необходимых для размещения данных), а наихудшее - 64 (когда только один блок данных WAFL, равный 4 KB, попадает в каждый чанк). Основное оценочное правило, если том имеет 1/N свободных блоков (включая 10% WAFL reserve, служебного резервирования файловой системы под ее собственные структуры), то ожидаемая величина будет близка к N (на практике, обычно лучше). Пример (romx): Половина диска пусты (1/2), то следует ожидать величину rate до 2. Четверть (1/4) свободна - до 4.
Наихудшая возможная величина для систем с менее чем 3 GB RAM равна 16 (Sic! romx), исключая системы типа FAS250, FAS270 и FAS270c. Для этих систем наихудшая величина равна 64.
Не спрашивайте меня почему так, я просто разместил объяву я просто перевел статью в KB.
На практике вполне можно достичь значительных величин фрагментации, если поставить такую цель, например при тестировании, ссылку на статью о котором я давал раньше, человек создавал том с fragmentation rate равным 22. При этом, с помощью программы Iometer, в течении 6 часов проводилась непрерывная случайная запись в файл размером 100GB 64-мя одновременными потоками
При этом, ухудшение производительности на фрагментированном с величной rate: 10 (как называет эту величину документация по reallocate - very unoptimized) составило примерно 15 процентов.
Таким образом, наихудшего значения фрагментации для записываемых данных (не для уже записанных!) можно достичь интенсивно записывая на почти заполненный том, с объемом свободного пространства на нем менее 1/16 от общего пространства.
Если еще внимательно подумать над вышенаписанным, то становится понятно, что фрагментация вовсе отсутствует для данных, помещающихся целиком в один кластер-”блок” WAFL 4KB, он никогда не разбивается на части, и принципиально сравнительно невысока для записываемых файлов, размерами менее одного “чанка” - 256KB, так как если уж у нас есть последовательный кусок места в 256KB на диске, то данные будут записаны в этот кусок, целиком, без разбивки.
На следующей неделе мы продолжим “сеанс черной магии с последующим ея разоблачением”, и рассмотрим другие темы, поднимающиеся нашими коллегами-конкурентами, в отношении продукции NetApp.
Начнем с “классики”. Ни один наш конкурент не обходит вниманием “проблему” фрагментированности записи на том файловой системы WAFL.
Будем считать, что люди здесь собрались взрослые, поэтому я уже могу рассказать вам правду откуда берутся дети как обстоит дело с фрагментацией на WAFL на самом деле.
Вопрос: Правда ли, что запись, даже последовательных фрагментов данных, происходит на системе хранения NetApp в “рандомном” порядке, и записанная порция данных оказывается фрагментированна по пространству диска?
Ответ: Да, в общем случае это так. Это прямое следствие того, что запись на WAFL (Write Anywhere File System) происходит “Anywhere”, повсюду, где это возможно, а не в строго заданные участки, как это происходит у практически всех других файловых систем.
Зато за счет этого WAFL такая быстрая на запись. Ведь даже “рандомная” запись превращается для системы в “секвентальную”, последовательную, а это дает заметный прирост общей производительности на реальных задачах, ведь, обычно, время записи есть довольно критичный параметр в реальной жизни.
Однако следствием этого является то, что после записи данные оказываются разбросаны по дисковому пространству, что должно ухудшить результаты чтения, так, “последовательное” чтение превращается в “случайное”. Да, это все так. Но давайте углубимся в детали.
Во первых значительную часть проблемы снимает кэширование. Не секрет, что кэширование чтения есть гораздо более эффективный и “прямой” процесс. А за счет того, что данные на запись практически не задерживаются в кэше (можно считать, что кэша “на запись” как такового, такого, какой он есть у конкурирующих систем, у NetApp нет вовсе. Все записываемые данные незамедлительно уходят на диск) весь объем кэш-памяти систем NetApp это кэш чтения, и он не заполняется постоянно висящими в нем данными, ждущими очереди сброса на диск, как это происходит у “обычныхtm систем хранения”.
Все пространство памяти - это кэш чтения.
Во вторых, в системе работает процесс, осуществляющий “сборку” последовательных цепочек данных в фоновом режиме (так называемый reallocate). Таким образом, некоторое время спустя, если процессор вашей системы хранения не нагружен предельно (а такое практически не встречается, да и нежедательно), и у него есть неиспользованные “тики”, свободное время, то ваша файловая система постепенно придет в более упорядоченное, дефрагментированное состояние.
То есть, если воспользоваться аналогией наших уважаемых конкурентов, подсмотренной в документе, патетически названном “Правда о NetApp”, где сравнивается поведение “Пришел домой, покидал вещи как попало, быстро от них избавился, зато наутро ищешь носки по всему дому”, то ситуация меняется тем, что за ночь придет горничная, и покиданные как попало вещи соберет и сложит по порядку.
К сожалению, и возможно кто-то из NetApp, кто меня читает, сможет ответить почему, было принято такое решение, что процесс reallocate необходимо вручную включить, так как по умолчанию “из коробки” он остановлен. Делается это просто, командой в консоли reallocate start. Но если слабоподготовленный админ это не сделает, то, в конечном счете, он действительно может получить довольно сильно фрагментированную систему с пониженными показателями чтения.
Таким образом ответ на вопрос “существует ли проблема фрагментации на системах хранения NetApp?” довольно прост. Фрагментация - есть, а вот особых проблем, связанных с ней, как правило, - нет. Фрагментация, строго говоря, это проблема на файловых системах “каменного века”, типа FAT, но WAFL это отнюдь не FAT, поэтому переоценивать эту опасность, и уж точно считать ее “основным недостатком NetApp”, как мне порой приходится слышать - необоснованно.
Чтобы не перегружать пост я опубликую вторую часть этого поста, с ответом на вопрос: “так какова же фрагментация на WAFL в реальной жизни “в граммах” - завтра.
Необходимым элементом IT-шного ландшафта, не только в нашей стране, являются, как мы их называем у себя “говнилки”, на языке же наших партнеров (они же “вероятные противники”) это зовется более интеллигентно - “FUD” или - “Страх, неопределенность и сомнения”.
Это сведения, которые выставляют продукцию конкурента “в нелучшем свете”, заставляя клиента беспокоиться и сомневаться в своем мнении, причем зачастую это именно намеренное представление каких-либо свойств как отрицательных.
Обычное дело, манипулировать впечатлением зачастую не слишком компетентного клиента.
Способы существуют самые разнообразные. “Да это все голимая китайщина, да у них дисковые полки делает китайский Xyratex, тот самый Xyratex, который, ну вы знаете, гонит дешевку, их в энтри-левеле очень любят продавать.” (Далее подразумевается, что раз какую-то часть оборудования производит китайская компания, то и вся она тоже “китайская”, то есть низкокачественная, совсем как тот фен, который мы купили на рынке)” Дело сделано. Клиент уже смотрит на продукцию конкурента с подозрением. Мы ведь ему не рассказали, что наши дисковые полки тоже делал тот же Xyratex (а то кто и еще менее известный). ;)
?? неважно что Китай на сегодняшний день производит подавляющее большинство микроэлектроники в мире, что на сегодня хайтек-заводы Китая - лучшие в мире, что подобные претензии со стороны России, давно не имеющей вообще никакого конкурентоспособного электронного производства просто смешны - дело сделано. Сомнения посеяны, ведь для малообразованного (в этой области) клиента “Китай” и “низкое качество” синонимы со времен покупки пять лет назад фена на рынке.
Казалось бы, ну что с того, что какие-то компоненты системы производятся на заводах компании-партнера. В наше время никто не делает ничего в одиночку, все компании связаны сотнями партнерских отношений между собой. Огромное количество оборудования производится по ODM-соглашениям. Наверное 95% ноутбуков, а то и все 100% производится 8-10 заводами малоизвестных массовому кругу китайских компаний, таких как Quanta, Compal, EliteGroup, Twinhead, а затем продаются как Apple, Toshiba, Compaq, Dell.
Межбрэндовая интеграция это давно уже ежедневная реальность.
Но мы же об этом умолчим, предоставляя додумывать клиенту. Вот уже и неопределенность, и сомнения.
“Да у них внутри, не поверите, Винда! Да-да та самая ЭксПи, как вот на этом компьютере!”
“Действительно”, думает клиент, “о какой надежности можно говорить, если уменя сынишка на прошлой неделе “повалил” домашнюю машину свежим видеодрайвером для своей новой дурацкой “стрелялки”. Винда - масдай, это понятно”.
?? неважно, что от это “ЭксПи” там используется только минимальное “ядро”, управляющее через спецдрайвера “железными” контроллерами, то есть по сути как интерфейс управления, и только. Внутри - винда, значит это ненадежно, непроизводительно и “непрофессионально” (еще один фетиш, кстати). То ли дело, какая-нибудь неизвестная система с непроизносимым названием. Сразу видно - “профессиональная”, “не для лохов”.
“Да они же не специалисты в этой области совсем, как можно быть специалистом в системах хранения, если они занимаются всем подряд, и ноутбуки у них, и принтеры, и фотоаппараты, естественно все получается средненькое. Да и вообще, как я слышал, у них это направление прикрывают, команда разработчиков уволена. Выпустили это поколение и все, больше разработок не будет, а через три года и обслуживание прекратят.”
Слухи тоже прекрасный метод. “?? вообще, то ли он украл, то ли у него украли, но осадок неприятный остался”
Я намеренно в примерах привел говнилки на разные компании (sapienti sat), чтобы никому обидно не было. :) В последующх статьях я подробнее остановлюсь на основных темах FUD для NetApp, распространяемых нашими коллегами-конкурентами. Возможно это даст будущим клиентам NetApp, которые, я не сомневаюсь, читают этот блог, достойные аргументы в диалоге с ними.