RAID-6: что это, и зачем нужно?
Десять лет жили себе, не тужили без него, и вот на тебе, счастье на нашу голову. Зачем нам этот RAID новый, или старых не хватает?
Получается что не хватает, и давайте смотреть чего именно.
Во-первых, почему о RAID-6, или “RAID c двойной четностью” заговорили именно сейчас?
Причина - в резком, и продолжающемся росте емкости единичного жесткого диска.
Количество байт на устройство становится все больше, а вероятность сбоя чтения, исчисляемая в случаях на количество прочитанных-записанных байт, остается практически неизменной. Я сейчас говорю не столько о надежности самого диска вида “сломался”, сколько о надежности математики чтения с поверхности дисков.
Допустим, что мы предполагаем (условно) вероятность сбоя чтения одного бита из ста миллиардов. Но это только кажущаяся большая цифра и низкая вероятность, так как она означает, что мы будем получать ошибку чтения примерно каждые 12 с половиной гигабайт прочитанной информации. Конечно, реальная вероятность сбоя значительно, на много порядков ниже, но она, тем не менее, не нулевая. Официальную величину можно найти в данных на тот или иной тип дисков у производителя.
То есть если раньше один случай вероятного сбоя вида “неверно прочлось и не исправилось математикой контроллера, oops…” был распределен на объем прочитанных байт, расположенных, например, на десятке дисков, то теперь, когда емкость одного диска увеличилась, количество дисков, несущих этот же объем байт, резко сократилось. ?? теперь вероятность сбоя дисковой группы резко выросла. Ведь теперь сбой возможен на гораздо меньшем количестве дисков. Допустим раньше у нас был массив в 4TB из 30 дисков 144GB. Создав на нем 6 групп RAID-5 4+1 мы получаем, что мы готовы перенести, без потери данных, до 6 сбоев диска, по одному в каждой RAID-группе.
Но времена меняются, и теперь 4TB это всего 5 дисков вида RAID-5 4+1. А вероятность в, условно допустим, 6 сбоев на такой объем осталась прежней.
Это значит, что на больших массивах, RAID-5, защищающий от единичного сбоя, больше не защищает ни от чего.
Это значит, что в случае дискового сбоя, на время ребилда RAID, а это время на дисках 146GB под нагрузкой занимает до суток, а на дисках большего размера, соответственно, больше, сообщают о величинах до 80-100 часов.
Готовы ли вы примерно на четверо суток оказаться без RAID для ваших данных вообще?
“Без RAID” (RAID-0, другими словами) потому что на время ребилда любой сбой чтения-записи, на любом диске, приведет к потере данных теперь уже гарантировано.
Конечно картинку я рисую несколько утрированно апокалиптическую, но тенденция именно такова, и игнорировать ее уже нельзя.
Показательная иллюстрация была найдена в документации NetApp.
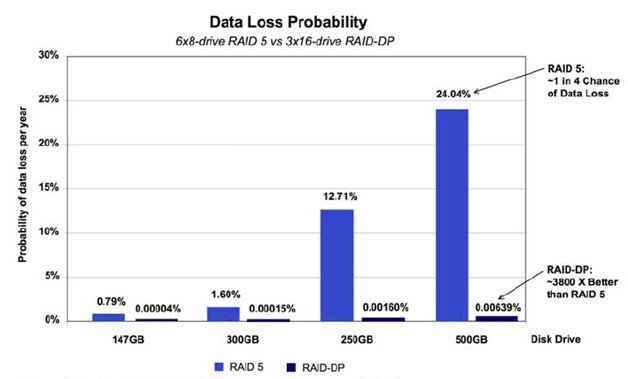
А это - данные HDS (чтобы вы не думали, что это все пропаганда в пользу одного вендора).
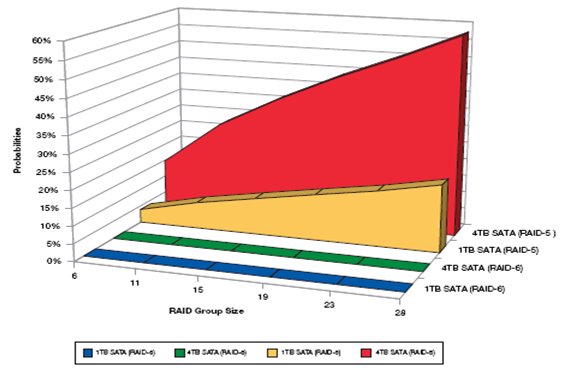
Отчасти задача, казалось бы, решается с помощью RAID-10 (RAID 0+1). При благоприятном стечении обстоятельств мы можем пережить отказ в половине дисков, однако, если эти диски из разных “половин” зеркала. Однако, как заметил еще Мерфи, обстоятельства склонны случаться в наихудшем из возможных вариантов.
??менно рост объемов на один диск, и, как следствие, повышающаяся вероятность сбоя “на шпиндель хранения”, вызвало тот факт, что сегодня практически все вендоры предложили в своих системах хранения реализации “RAID с двойной четностью”.
Ну хорошо, скажете вы. Отчего мы тогда все не применяем RAID-6 повсеместно?
Увы, один, но значительный минус присутствует. Будучи сравнимой в показателях производительности при Random Read, Sequential Read и Sequential Write, RAID-группа с типом 6 как правило сильно проигрывает (практически на треть!) на Random Write, что практически лишает RAID-6 шансов на использование в задачах, критичных к быстродействию по тому параметру, например OLTP-базы данных, и подобных им. Более того, практически, применения RAID-6 в его классическом виде, возможно только на весьма ограниченном пространстве задач, таких, как, например бэкапы, или DSS-базы, то есть задачи без Random Write. По крайней мере Best Practices вендоров тут единодушны.
На фоне этих невеселых сведений особняком стоит реализация “RAID с двойной четностью” от NetApp - RAID-DP.
Будучи собственной, независимой реализацией RAID-6, полностью соответствующей определению RAID-6, данном SNIA, она принципиально отличается от собственно RAID-6 тем, что показатели на Random Write на такой дисковой группе не ухудшаются, как это характерно для “классического” RAID-6.
Если совсем буквоедствовать, то ухудшение присутствует, но в пределах нескольких процентов, против примерно 20-33% у “классического RAID-6″.
Это единственная такая реализация RAID-6 из существующих на рынке.
Это позволило рекомендовать NetApp использовать RAID-DP как тип “по умолчанию” для всех своих систем хранения.
Больший же расход дисков на “погонный usable гигабайт” компенсируется тем, что в случае использования RAID-DP мы можем использовать более длинные RAID-группы, без опаски за надежность хранимых данных. Так, например, если ранее, с RAID-4 NetApp рекомендовал использовать группы по 7+1 дисков, то в случае RAID-DP рекомендации говорят о 14+2-дисковых группах (а максимально возможно 28!), как можно видеть, количество дисков, которые мы отдаем за обеспечение отказоустойчивости не увеличивается, а надежность растет, как мы показали ранее.
Dave Hitz:
С обычным RAID, мы рекомендуем пользователям создавать массивы RAID из 7 дисков плюс 1 parity disk. При использовании RAID-DP, мы рекомендуем создавать массив из 14 дисков, плюс 2 parity disks. Таким образом, это 2 parity disks на каждую полку с 14 дисками. При этом математика говорит, что RAID-DP на 14 дисках много, много безопаснее, чем обычный RAID на 7 дисках.
??нтересно, а сохраняется ли высокие показатели на Random Write у групп RAID-DP после переполнения кэша массива? У EMC, в принципе, пока кэш не переполнился показатели RAID-5 и RAID-6 на Random Write примерно одинаковые - “Однако, пока рабочая нагрузка может передаваться от кэша без принудительного сбрасывания на диск, RAID 5 и RAID 6 имеют сходное поведение с точки зрения времени ответа.”
Тут надо понимать принципиальную разницу. У NetApp вообще нет кэша записи в его традиционном понимании как он сделан у остальных массивов. У него есть некая буферная память, где собирается полный страйп записи, и атомарно переносится на диск, то есть в кэш-памяти как таковой ничего не хранится, и она целиком использована под чтение. Этакая транзакционная файловая система.
За счет же того, что она устроена таким образом, что данные не перезаписываются, эта запись-”сброс кэша” происходит дловольно быстро, и целым страйпом. ??менно за счет того, что запись происходит целым подготовленным страйпом и объясняется то, что скорость записи на RAID-DP не падает по сравнению с “не-DP”.
Остальные массивы вынуждены записывать random-данные поблочно, а не очень эффективным страйповым методом.
То есть по сути любая random write в NetApp становится sequental, так как так устроена его файловая система. Подробнее смотрите в предыдущем посте, где рассматривается внутреннее устройство WAFL.
Странно - почему это “RAID-группа с типом 6 как правило сильно проигрывает (практически на треть!) на Random Write”? У R5 wp=4, у R6 wp=6. Не на треть, а на 50%.
Второй вопрос - я всегда думал, что безпроигрышность NetApp с RAID-DP связана с исключительно технологией NVRAM/WAFL, а не с устройством RAID. Вот HDS тоже чмырит RAID6 от EMC со ссылками на Intel, они совершенно правы - у EMC более медленная реализация R6. А у NetApp что-же, какая-то третья, неизвестная другим производителям реализация R6 (DP)? Что-то я засомневался…
Я при подготовке текста брал исходные данные с http://storagenerve.com
http://www.storagenerve.com/2009/02/hitachis-hds-raid-6.html
http://www.storagenerve.com/2009/02/netapps-raid-dp-enhanced-raid-6.html
http://www.storagenerve.com/2009/02/sun-storageteks-raid-6-implementation.html
http://www.storagenerve.com/2009/02/emc-symmetrix-dmx-raid-6-implementation.html
Ну и в двусмысленных местах округлял в пользу компетитора, конечно, что, мне не жалко :)
Ромх, все же я не получил ответа на оба свои вопроса :)
Вы, как гуру, ответьте, плз. Может я жестоко ошибаюсь и пока не знаю об этом.
Что касается RAID-DP = RAID-6, то тут вот какая история. Долгое время NetApp говоил, что RAID-DP это не RAID-6 (оно и понятно, та же характеристика на записи совсем иная).
Но потом было принято волевое решение сделать все наоборот, и говорить что RAID-DP это RAID-6 (что тоже в каком-то смысле понятно, DP полностью соответствует формальному определению SNIA для RAID-6).
Причина довольно простая, когда выставляются предложения на тендер, в которм в условиях строго написано “RAID-6 и только”, бывает непросто объяснить, что RAID-DP - “same same but different”, как говорят у нас, в Таиланде :)
Поэтому было принято рещение считать RAID-DP - RAID-ом 6, и все.
С точки зрения того, как там все устроено сложно разобраться без бутылки. Ранее, в статье про устройство WAFL уже указывалось, что WAFL такая хитрая штука, что RAID по сути является частью этой “файловой системы”, и это многое меняет в принципе. Поэтому просто так тут не поделишь: тут вот софт, тут диски, тут кэш, и так далее. Там все вместе, взаимопроникает. Поэтому, если буквоедствовать, то да, у RAID-DP иная реализация, поскольку так никто больше не делает.
Вот через три недели NetApp Innovation 2009, и, если ты в Москве, то рекомендую сходить, найти там Рому Ройфмана, взять его в кулуарах за пуговицу, и расспросить. ?? если он будет в настроении, а такое бывает, то он много умнее чем я сможет рассказать.
Советую воспрользоваться этой возможностью.
Ага, спасибо. А про 7 апреля в курсе и даже зарегистрировался. РР знаю, бывает обращаюсь по рабочим вопросам (:
Что же касается производительности RAID-DP на запись, то повторю уже написанное выше. Насколько я все это понимаю, принципиальный момент, который и, как следствие, позволяет получить RAID-6 без потери на быстродействии в Random Write, в том, что в NetApp Random Write всегда становится Sequental. Там просто нет Random Write вообще, по свойствам WAFL. Плюс то, что в системе сразу готовится полный страйп в NVRAM на запись, что практически очень сложно достичь в случае “классических” систем.