NAS и SAN. Что это. Чем схоже и чем отличается.
Часто приходится сталкиваться с принципиальным непониманием у клиентов разницы между NAS и SAN-подключением внешнего дискового массива.
??так, что есть что, чем отличается друг от друга и какие плюсы-минусы у каждого.
NAS хорошо знаком большинству пользователей, использующих в локальной сети своей организации файловый сервер. Файловый сервер - это NAS. Это устройство, подключенное в локальную сеть и предоставляющее доступ к своим дискам по одному из протоколов “сетевых файловых систем”, наример CIFS (Common Internet File System) для Windows-систем (раньше называлась SMB - Server Message Blocks) или NFS (Network File System) для UNIX/Linux-систем.
Остальные варианты встречаются исчезающе редко.
SAN-устройство, с точки зрения пользователя, есть просто локальный диск.
Обычные варианты протокола доступа к SAN-диску это протокол FibreChannel (FC) и iSCSI (IP-SAN). Для использования SAN в компьютере, который хочет подключиться к SAN, должна быть установлена плата адаптера SAN, которая обычно называется HBA - Host Bus Adapter.
Этот адаптер представляет собой с точки зрения компьютера такую своеобразную SCSI-карту и обращается с ней так же, как с обычной SCSI-картой. Отсылает в нее команды SCSI и получает обратно блоки данных по протоколу SCSI. Наружу же эта карта передает блоки данных и команды SCSI, завернутые в пакеты FC или IP для iSCSI.
На приведенном рисунке вы видите 1 диск, подключенный с NAS-устройства (внизу), и один диск, подключенный по SAN по протоколу iSCSI.
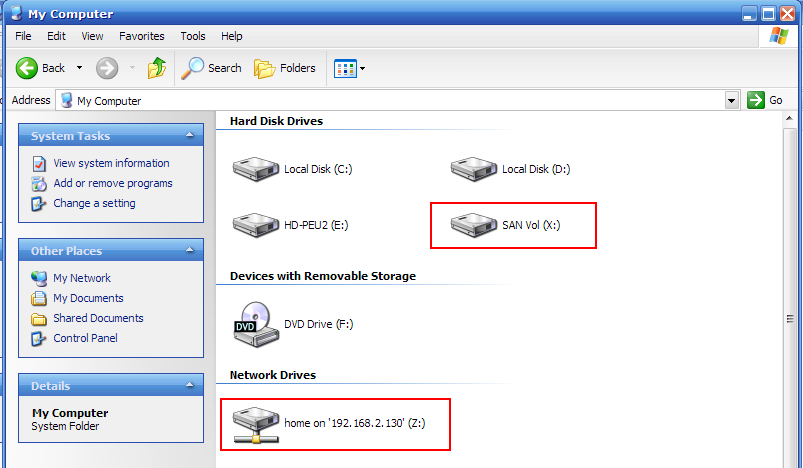
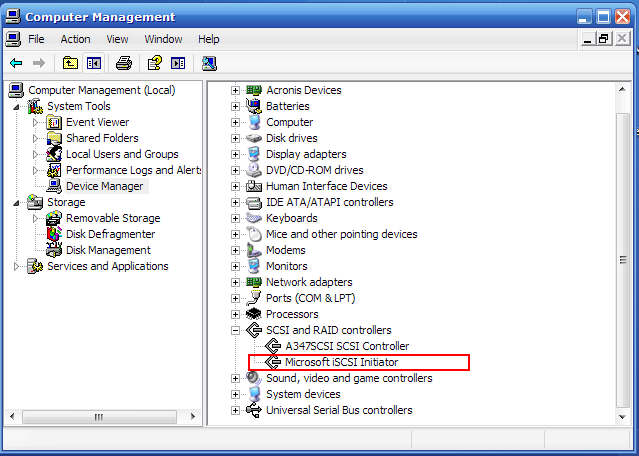
Здесь мы видим, как SAN-диск виден в диспетчере устройств. Microsoft iSCSI Initiator это софтверный (программный) адаптер протокола iSCSI, представляющийся системе как SCSI-карта, через которую идет обмен данными с SAN-диском.
В случае FC на его месте находился бы HBA FC, он тоже является с точки зрения OS “SCSI-адаптером”.
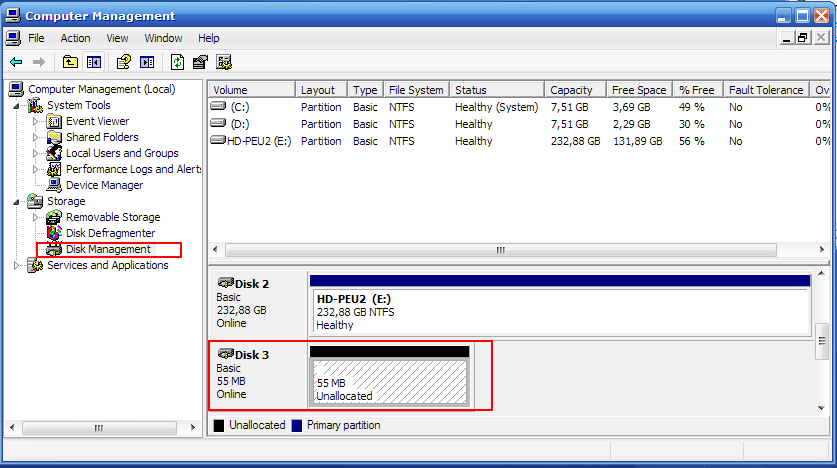
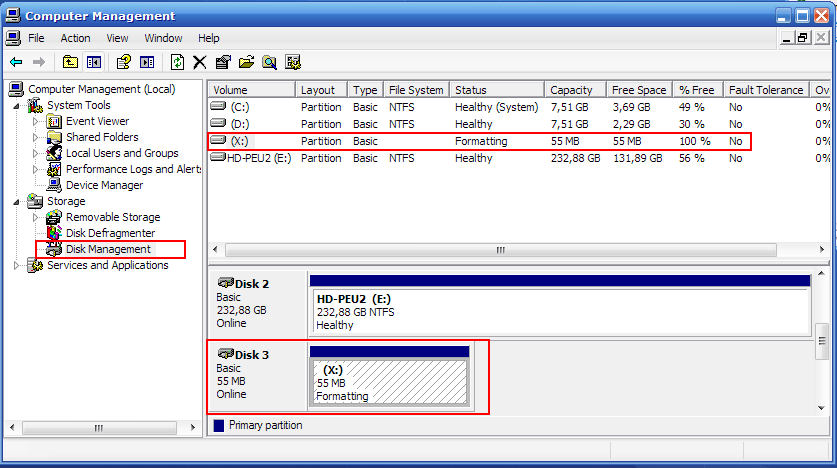
Когда мы подключаем компьютер к SAN, нужно сделать rescan all disks и вскоре в Disk Manager появится новый неотформатированный раздел. На нем обычным образом можно создать партицию, отформатировать ее и получить локальный диск, который физически будет являться выделенным разделом на большой системе хранения и соединяться с компьютером оптическим кабелем FC или сетью gigabit ethernet в случае использования iSCSI.
Каковы же плюсы и минусы обеих этих моделей доступа к данным системы хранения?
- NAS работает поверх локальной сети, используя обычное сетевое оборудование.
- Он работает преимущественно с файлами и информацией, оформленной как файлы (пример: документы общего пользования, word- и excel-файлы).
- Он позволяет коллективное использование информации на дисках (одновременный доступ с нескольких компьютеров).
- SAN работает в собственной сети, для использования которой нужен дорогостоящий Host Bus Adapter (HBA).
- Он работает на уровне блоков данных. Это могут быть файлы, но это могут быть и нефайловые методы хранения. Например база данных Oracle на т.н. raw-partition.
- Для компьютера это локальный диск, поэтому коллективное использование информации на SAN диске обычно невозможно (или делается очень сложно и дорого).
Плюсы NAS:
- дешевизна и доступность его ресурсов не только для отдельных серверов, но и для любых компьютеров организации.
- простота коллективного использования ресурсов.
минусы NAS:
- невозможно использовать “нефайловые” методы.
- доступ к информации через протоколы “сетевых файловых систем” зачастую медленнее, чем как к локальному диску.
Плюсы SAN:
- можно использовать блочные методы доступа, хранение “нефайловой” информации (часто используется для баз данных, а также для почтовой базы Exchange).
- “низкоуровневый” доступ к SAN-диску обычно более быстрый, чем через сеть. Гораздо проще сделать очень быстрый доступ к данным с использованием кэширования.
- Некоторые приложения работают только с “локальными дисками” и не работают на NAS (пример - MS Exchange)
Минусы SAN:
- трудно, дорого или вовсе невозможно осуществить коллективный доступ к дисковому разделу в SAN с двух и более компьютеров.
- Стоимость подключения к FC-SAN довольно велика (около 1000-1500$ за плату HBA). Подключение к iSCSI (IP-SAN) гораздо дешевле, но требует поддержки iSCSI на дисковом массиве.
??так, что же общего между этими двумя методами? Оба этих метода используются для “сетевого хранения данных” (networking data storage).
Что из них лучше? Единственного ответа не существует. Попытка решить задачи NAS с помощью SAN-системы, как и обратная задача, зачастую есть кратчайший путь потратить большие деньги без видимой выгоды и результата. Каждая из этих “парадигм” имеет свои сильные стороны, каждая имеет оптимальные методы применения.

