Я решил не раздувать прошлый пост, упихивая в него всю тему.
Сегодня подробнее о том, почему, и как именно вы получите “больше от того же NetApp” при использовании VMware на NFS.
Простое и эффективное использование всех фич NetApp, таких как thin provisioning (динамическое выделение пространства тому по мере его потребности в месте, а не сразу в момент нарезки тома или LUN), дедупликация, снэпшоты.
Почему оно хорошо работает с NFS и что ему мешает работать также хорошо на FC/iSCSI?
Thin Provisioning (подробнее было здесь)
Я уже ранее писал о thin provisioning. Это любопытная технология, которая позволяет экономить место на дисковой системе хранения за счет того, что, в отличие от традиционного метода, место для занимающего пространство объекта, будь то LUN или файл, например тот же VMDK, выделяется и резервируется не в момент создания, а по мере заполнения его реальным содержимым.
Простой пример. Вы администратор системы хранения и у вас есть 1TB. Но кроме терабайта пока свободного места у вас есть пользователи со своими проектами. Например к вам пришли трое, каждый желает получить по 500GB под свои базы данных. У вас есть несколько вариантов решения. Вы можете выделить первым двум запрашиваемые 500 и отказать третьему. Вы можете урезать их треования и выдать всем троим по 330GB вместо просимых 500.
В обоих случаях вы окажетесь с полностью “занятым” стораджем, при том, что вы точно знаете, что в ближайший год все три базы едва ли по 50-70GB объема наберут, остальное же выданное место будет лежать “про запас”, “чтобы два раза не ходить”, распределенным и не доступным другим нуждающимся. Обычное дело, всем знакомо.
В случае использования thin provisioning-а вы смело выдаете всем троим по просимым 500GB. Все трое видят для себя доступным LUN размером 500GB, ура. Они создают на нем базы, каждая из которых постепенно растет и использует место. С точки зрения же вас, как администратора, свободное пространство на дисках, общей емкостью в 1TB, несмотря на то, что на нем лежит три якобы 500GB LUN, уменьшилось всего на 50*3=150GB, и вы все еще имеете 850GB свободного места, постепенно уменьшающееся по мере роста реального размера баз. Придет к вам четвертый - получит пространство под свои задачи и он.
Традиционный вопрос и традиционный ответ.
Q: А как же фрагментация? Ведь мы еще со времен Windows 95 привыкли отключать динамически изменяемый своп и фиксировать его для достижения лучшей производительности? Если мы предоставим LUN-у рсти как ему вздумается, то он начнет писаться куда попало, а не подряд?
A: Ну наверное для Windows на FAT это действительно верно. Но в случае WAFL это особого смысла не имеет. WAFL как файловая система устроена так, что он в любом случае будет писать “вразнобой” (см. статью про устройство WAFL), “куда попало” AKA “Write Anywhere”. То есть выделили-ли вы фиксированный LUN, или предоставили ему расти самостоятельно (autogrow), хоть так, хоть сяк, оно будет работать, с точки зрения файловой системы, одинаково. ?? если вас устраивало быстродействие в случае традиционного provisioning-а “одним куском”, то нисколько не медленнее оно будет и в случае thin provisioning-а.
Почему это хорошо работает для NAS, и часто не так хорошо для SAN?
Дело в том, что в случае NAS система хранения обладает полной информацией о хранимых данных. Ведь она создает и поддерживает на своей стороне файловую систему, и знает все о том, что у нее хранится. В случае же хранения LUN, она просто предоставляет внешнему пользователю “массив байт”, и далее не знает ничего о том, что и как там на нем происходит.
Вся информация, которой она располагает, это то, что вот эти байты были “потроганы”, и, значит, скорее всего, содержат информацию, а вот эти - нет, и скорее всего они пусты и не используются.
Простой пример, приведший к созданию опции Space Reclamation в новых версиях SnapDrive for Windows.
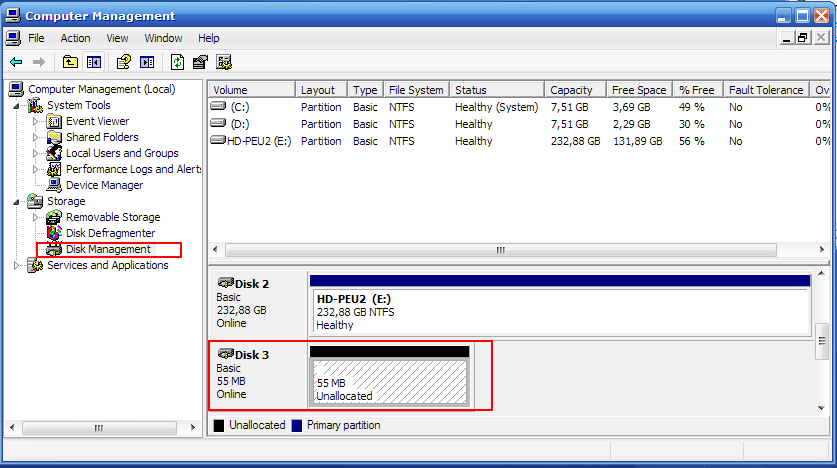
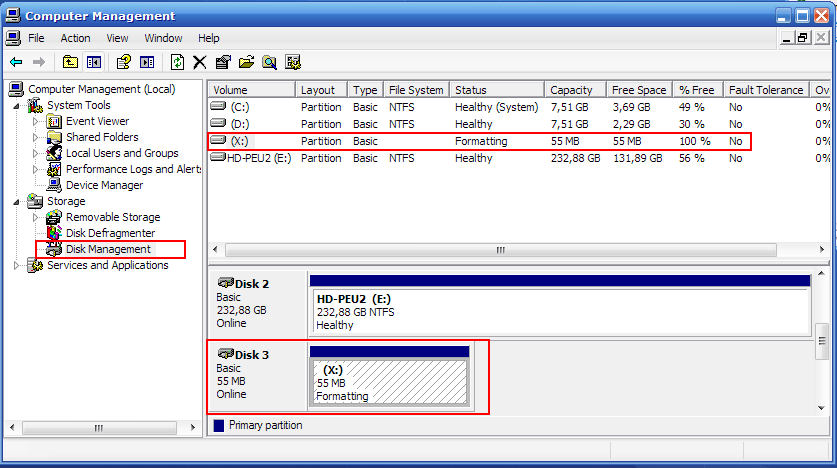
Мы создаем LUN размером 500GB и размещаем на нем файловую систему, например NTFS. Мы форматируем ее, создаем на ней некую структуру файловой системы, и начинаем записывать данные. Спустя какое-то время мы записали на данный LUN 90% его емкости и решили его почистить от ненужного, надеясь за счет thin provisioning-а получить больше свободного места на системе хранения. Но, после удаления более ненужной информации, наш LUN на системе хранения продолжает занимать все те же 450GB, как и до чистки. Почему?
Потому что SAN-сторадж ничего не знает о том, что на нем произошла чистка. Вы знаете, что отличие свободного от занятого блока, с точки зрения файловой системы, это просто наличие специального атрибута блока “свободен, можно использовать повторно”. С точки зрения системы хранения все 450GB нашего LUN-а несут какую-то информацию, а таблица “занято-свободно” файловой системы для стораджа недоступна.
??менно для решения такой проблемы и была создана опция Space Reclamation. SnapDrive, работая “послом” на уровне OS и взаимодействуя с драйвером файловой системы, сообщает “вниз”, своему стораджу, что там “наверху” происходит, какие из ранее использованных блоков можно опять считать незанятыми и освободить их.
Но такое доступно, повторюсь, только при использовании нового SnapDrive.
Зато просто и естественно получается при использовании стораджа как NAS. Веь в данном случае он сам следит за тем, какие блоки занимаются и высвобождаются.
Следовательно, thin provisioning на NAS получается, обычно, гораздо эффективнее.
Дедупликация.
Подробнее и в деталях о дедупликации можно почитать на русском языке в статьях “A-SIS: Дедупликация созрела” и “Насколько безопасна дедупликация?”
Кроме того, хочу обратить ваше внимание на русскоязычную рассылку, которую проводит российский дистрибутор NetApp - компания Verysell. Ссылка на уже вышедшие выпуски находится справа, в колонке “Ссылки” - “Русскоязычные документы”.
Это технология, при которой система обнаруживает в хранимых данных идентичные блоки, оставляет один, а на второй ставит своеобразные “хардлинки” на уровне файловой системы WAFL. То есть, с точки зрения пользователя, как раньше у него лежал в его домашней папке разосланный всем по компании документ, так и сейчас лежит, также как у сотни его коллег. На деле блоки данных этого документа хранятся в единственном экземпляре, просто логически доступны из множества пользовательских папок системы хранения.
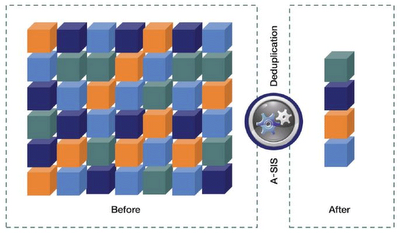
Точно также все обстоит и в случае использования, например, баз данных. Если в базе данных у вас есть, например, пустые поля, или повторяющиеся записи, то эти поля не будут занимать блоки, в которых они расположены, а лишь одну копию, и “линки” на этот блок из множества других мест.
Так как это происходит на уровне файловой системы, то для пользователя, программы или базы данных это полностью прозрачно. Дедуплицированный же объект будет занимать на диске место значительно меньшее своего физического размера.
Если вы используете “классический метод” подключения LUN к ESX-серверу, с созданием на нем VMFS и хранением в ней файлов виртуальных дисков VMDK, то вы тоже можете воспользоваться дедупликацией. Так как она работает на уровне тома WAFL, то она заработает и для LUN-ов.
Однако вот в чем хитрость. При использовании дедупликации для LUN, экономию места вы увидите на уровне “администратора системы хранения”, а не “администратора VMware”. То есть после завершения postprocess-цикла дедупликации вы не увидите больше места на LUN. Но вот зато на томе NetApp, где располагается этот LUN, вы действительно получите больше места (например для размещения снэпшотов), так как физический объем LUN-а уменьшился, относительно содержащего его тома.
А вот если мы дедуплицируем содержимое NFS-шары, то вот прямо свободное место, непосредственно доступное админу VMware на этой шаре, в результате и получаем. Опять же по вышерассмотренной причине.
Снэпшоты - один из краеугольных камней системы хранения NetApp и одна из ее самых главных технических фишек. Мгновенные копии состояния системы хранения, не занимают в момент создания места, не ухудшают при использовании производительность системы в целом и весьма просты в применении.
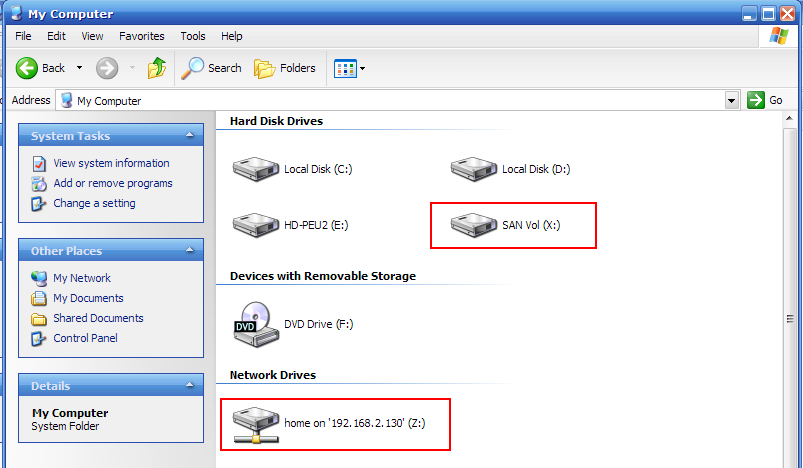
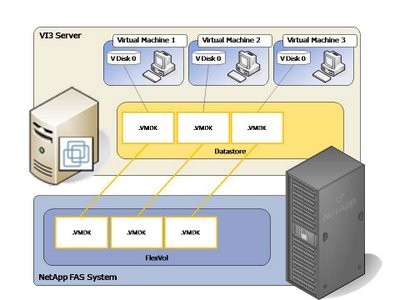
Традиционный подход это подключение LUN по FC или iSCSI, форматирование его в VMFS и создание на нем datastore, для размещения в datastore файлов виртуальных дисков VMDK.
Обычно, когда мы не ограничиваемся одной-двумя виртуальным машинами, мы объединяем и группируем диски виртуальных машин по датасторам. Тут у нас Эксченджи, тут файловые сервера, а тут - базы данных. Это облегчает администрирование, увеличивает надежность сервисов, и улучшает производительность, группируя сходную нагрузку в пределах одного потока ввода-вывода.
Но, как известно бэкап - ничто, без процесса восстановления. А вот с восстановлением все будет непросто. Так как в снэпшоте у нас окажется LUN целиком, то и восстановить его, привычным образом через “snap restore ” мы можем только целиком, вместе со всеми VMDK от разных машин. Хорошо ли будет из за сбоя на одном сервере откатывать всю группу? Сомневаюсь.
Конечно есть выходы, можно смонтировать снэпшот как отдельный датастор, и из получившегося “датастор-прим” вытащить только нужные нам VMDK, а затем перенести их в основной датастор, заменив ими текушие файлы…
Но как-то… неаккуратненько.
Какой же выход?
Можно перейти от LUN/VMFS, рассмотренных выше, к LUN/RDM. То есть каждой виртуальной машине мы цепляем свой, созданный специально для нее LUN (или, чаще, два LUN. Один под систему, второй под swap и temp или /var). Казалось бы, мы решаем проблему с недостаточной гранулярностью восстановления, так как в данном случае мы сможем восстановить любой желаемый виртуальный диск, любой виртуальной машины по выбору.
Однако это хорошо работает только при сравнительно небольшом количестве виртуальных машин. Во первых, “датацентр” VMware, включающий в себя все входящие в него ESX-сервера, объединенные процессом VMotion, ограничен в количестве используемых на нем LUN-ов числом 254 LUN-а.
Да и управление, например, двумя-тремя десятками виртуальных машин, каждая по два-три LUN в RDM, все эти LUN, как их не документируй, обязательно блудят и путаются. Решение для сильных духом и очень аккуратных админов.
Во вторых, мы в полный рост столкнемся с проблемой “заблудившихся LUN-ов”. Если наша виртуальная машина на одном из ESX-серверов использует LUN/RDM, то _все_ остальные ESX-сервера, входящие в “датацентр” будут видеть этот LUN как неиспользуемый, не понимая, что это RDM LUN для виртуальной машины. ?? существует весьма серьезная опасность, что однажды вы его таки отформатируете как незадействованный, в VMFS, вместе со всем его содержимым. Спрятать его нельзя, так как он должен быть доступен всем входящим в “датацентр” серверам для работы VMotion и перемещении нашей виртуальной машины между хостами. Это на самом деле серьезная опасность.
Таким образом при использовании снэпшотов на NFS-томе вы можете получить гораздо более “гранулярный” и удобный в использовании результат как при бэкапе, так и при восстановлении.
Как, вы все еще думаете, использовать ли для вашего VMware наш NFS? ;)