VMware на NFS: не только NetApp
Еще несколько деталей о NFS, чаще неспецифических для NetApp, но не менее важных и интересных.
Очереди Ввода-вывода.
Если вы используете в качестве datastore LUN под VMFS, то ввод-вывод вашего ESX, неважно FC или iSCSI, будет ограничен одной очередью ввода-вывода на LUN, для всех VM хранящих свои виртуальные диски в VMFS data store на нем. Ведь ESX обращается к одному единственному LUN, с точки зрения ввода-вывода это одно SCSI-устройство, и параллельность ввода-вывода тут невозможна или очень ограничена.
В случае NFS вы можете использовать произвольное количество очередей ввода-вывода. Каждая VM, хранящая свои виртуальные диски на data store на NFS-шаре, будет иметь индивидуальную и независимую от других очередь ввода-вывода (IO queue).
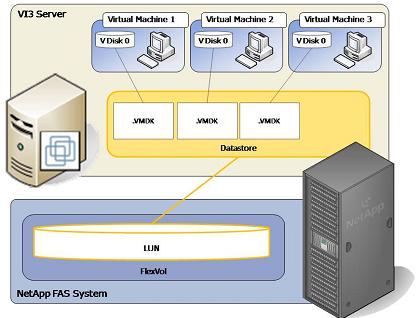
VMFS LUN. Одна очередь ввода-вывода ко всем VM на data store.
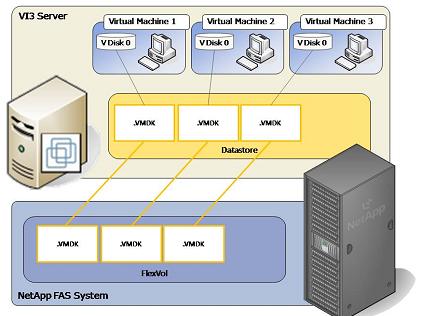
NFS Data Store. Каждая VM имеет собственную очередь ввода-вывода.
Bandwidth Is not a Speed
В значительном количестве случаев при переходе с FC на NFS вы, как ни странно, можете даже выиграть в скорости.
“Как же так?” - наверняка спросите вы, “Ведь всем известно, что скорость FC это 4 GB/s, а NFS в случае 1GB Ethernet работает на 1GB/s, значит NFS просто обязана работать вчетверо медленнее!”
Ответить нетрудно. “Полоса пропускания” (англ. “bandwidth”) не равно “Скорость” (англ. “Speed”). ??, к слову, не всегда равно “Производительность” (англ. “Performance”). Смешивать эти понятия будет большой ошибкой.
Я уже писал об этой “смысловой коллизии” раньше, процитирую себя вкратце:
“Скорость” интерфейса передачи данных зависит прежде всего от приложения, с ним работающего, а вовсе не от его “пропускной способности” в гигабайтах в секунду, до тех пор, пока мы не достигаем предела производительности интерфейса.
Ввод-вывод VMware ESX производится мелким блоками (4-8kb), и при этом предельно рандомно (что неудивительно для системы, хостящей множество независимых процессов множества виртуальных машин). При таком характере ввода-вывода роль играет не bandwith интерфейса, а его латентность и производительность в IOPS. А вот тут уже NFS имеет очень хорошие показатели, за счет чего и выигрывает в этих гонках. Так что, если при переходе с 4Gb/s FC на 1Gb/s NFS вы еще и выиграете в производительности, то не ищите, где же вы ошиблись. Это вполне вероятный поворот дела.
Увеличивать и уменьшать datastore без необходимости ковырять приложения и ESX.
??нтересной особенностью использования datastore на NFS-томе NetApp является то, что вы можете не только увеличивать его размер, но, при необходимости и уменьшать, причем и то и другое без какого-либо колдовства с сервером ESX или виртуальными машинами, чтобы они могли это увидеть и использовать.
Если увеличение это частая и в целом довольно обычная процедура, то вот уменьшение для LUN задача не из простых, а порой и вовсе нерешаемая.
Зато для NFS-тома NetApp вы вольны делать изменение в обе стороны.
Роман, ты же сам знаешь, как можно отлично работать с луном. Создать 1Тб лун с -o noreserve, на томе autosize, и все отлично работает.
Причем, авторасширение тома работает корректно, в случае с nfs/cifs не корректно (вернее не так как надо).
Не-не. Вот смотри, у нас есть LUN. Мы на него, на весь размер, создали файловую систему VMFS. Теперь нам понадобилось его увеличить. Увеличить - без проблем. Увеличиваем LUN, потом добавив Extent увеличиваем до нового размера VMFS.
А теперь - уменьшить?
А? Э… :)
Никак.
А в случае NFS share - пожалуйста, в обе стороны.
Я понял. Первый вопрос зачем уменьшать?
Второй вопрос как ты забьешь 1 Тб?
Можно конечно использовать asis, оно уменьшить данные на томе, но это как говориться, выдергивание гланд через з..
1. Ну мало ли, не всегда же потребность в пространстве увеличивается :) Удобно, когда можно изменять занимаемое пространство в обе стороны, а освобожденное отдавать более нуждающемуся.
2. Не понял вопроса. Что именно забью?
“Мы на него, на весь размер, создали файловую систему VMFS.”, т.е. на 1 тбайт ты создал ФС VMFS, я так понимаю ее надо же забить полностью данными?
Не забывай Vmware видит 1Тбайт. Реально на массиве это будет столько сколько реально занимают данные, причем оно АВТОМАТ??ЧЕСК?? будет увеличиться, если место на томе, где находиться лун, будет кончаться.
Обратно уменьшить том (на котором лун) беспроблембно не получиться, в отличии от NFS, с этим согласен. Но мне трудно представить, насколько часто это может понадобиться, возможно когда везде уже предел по свободному месту.
В качестве восстановления через snapshot, NFS/CIFS конечно гораздо лучше.
Роман, поясните плз несколько вещей:
1. Я правильно понимаю, что сам по себе NFS особо не причем и любая сетевая ФС даст прирост в производительности (по сравнению с локальной ФС), засчет возможности работать с хранилищен через отдельные коннекции?
2. В посте сказано, что каждая виртуалка использует свою коннекцию. Означает ли это, что каждая виртуалка должна коннектиться к “своему” LUN’у? Ведь если несколько VM будут соединяться с одним луном, то чем это отличается от локального стореджа с одним луном?
3. ??нтересно, что внутри серверов NetApp, т.е. какие там используются мамка/контроллеры/диски?
Alex: А у нас большой набор сетевых файловых систем вообще? 8-) Я так вот, если честно, даже в Википедию за этим слазил. http://en.wikipedia.org/wiki/Network_file_system
Да нет, при чем. Дело в том, что, во первых, он, в реализации, довольно прост и имеет минимум накладных расходов и “оверхеда”.
Например с CIFS такое не прокатывает, чаще всего.
Во вторых ESX поддерживает только NFS и больше ничего.
То есть может и с каким-нибудь AFS (для примера название) тоже что-то получилось, но ESX о нем не знает, так что это теоретический вопрос.
Что же касается преимущества в скорости, то оно обеспечивается далеко не столько ограничением в одну очередь ввода-вывода, не зря я об этом только в самом крайнем посте темы упомянул. Хотя среди всего прочего - да, это тоже свою роль играет, наверное, особенно в случае _реально очень большого_ потока ввода-вывода, заполняющего всю очередь. Но это надо стараться.
Прежде всего, как я понимаю, роль играет низкая латентность, присущая протоколу, и вызванные этим лучшие показатели по IOPS.
2. Нет, там говорится про “одну очередь ввода-вывода”. Очередь ввода-вывода это такая структура в OS, куда поступают команды “считать байт по адресу A, записать байт по адресу Б”. В случае FC/iSCSI такая очередь будет одна на LUN (где, обычно, несколько VM), а в случае NFS такая очередь будет у каждой VM своя, так каждая VM будет не читать-писать байты на некоем общем LUNе, а будет работать со своим файлом виртуального диска на NFS-шаре самостоятельно.
3. Там любопытно. Я где-то ранее писал в блоге об этом.
Раньше было много вариантов. Первый NetApp был вообще на 486-м процессоре. Потом были разные пентиумы, и даже Alpha AXP. Дольше всех продержался MIPS он был еще на FAS250/270. Сейчас только x86(64). Xeon на 3020 и 3050, Opteron на 3040, 3070 и 6000, Celeron на 2000.
Но собственно цимес там не в железе, на самом деле, а в софте, в Data ONTAP. Ну и в файловой системе WAFL. Это то, что делает NetApp NetApp-ом.
romx, спасибо за ответы!
еще такой вопрос: нет ли у вас результатов замеров IOPSов для систем NetApp? в архивах блога смотрел, но там статьи про бенчмарки покоцанные..
Я поищу, но политически грамотным будет воспользоваться результатами официальных бенчмарков - SPC-1 и SPEC SFS.
Роман, все последние статьи про NFS относятся к Vmware. А есть ли опыт переползания с LUN’ов на NFS для физических машин? Насколько проседаем по производительности в этом случае, в частности для Оракла?
У меня задача уменьшения лунов уже встала во весь рост, а SnapDrive для многопроцессорных SPARC’ов, боюсь, сильно дорог.
sanet: сам я не специалист в Оракле, но вот ildarych, тот который не верит, что LUN иногда и уменьшают ;) - как раз оракловый админ с NetApp-ом (правда на FC, как я знаю). Попробуйте спросить у него.
Далее. Можно для затравки почитать переведенную статью “Oracle on NFS” из весеннего выпуска TechONTAP. Там есть и ссылки на тесты производительности, посмотрите.
http://www.vd.verysell.ru/files/ie/330_4_DOCUMENT_oracle_on_nfs.pdf
Например под Linux.
http://www.netapp.com/library/tr/3495.pdf
Вся пополняемая библиотека переводов:
http://www.vd.verysell.ru/suppliers/netapp/documentation
??меет смысл также посмотрть Best Practices Guide про Oracle
http://media.netapp.com/documents/tr-3369.pdf
Ну а кроме этого в блогах Нетапперов покопаться.
http://www.netapp.com/us/communities/communities-blogs.html
Блог Санджая давно не обновляется, возможно переехал
http://netappdb.blogspot.com/
Зато есть живой:
http://blogs.netapp.com/databases/
А, Sanjay Gulabani теперь Account Manager, судя по LinkedIn :)
Кстати, на sql.ru в форумах есть Alex Roudnev, он тоже знатный оракловод, и у себя в Америке тоже на NetApp сидит и любит его. Обратите внимание на его посты в форуме sql.ru.
romx, спасибо, проштудирую. В принципе, если даже датафайлы оставить на лунах, ничто не мешает лить на NFS файлы экспорта, архивлоги и т.п.
Ildarych, можете прокомментировать?
Sanet, а можно более подробно?
Насколько я понял, некий Sun сервер подключён по FC, и у вас кончилось место на массиве, а вы предварительно отдали под него все свободное место, грубо говоря один том, в нем один лун и это все на одну полку?
Как подключать правильно NFS и какая скорость будет по NFS, есть в ссылках которые давал romx. Сам я лично с Oracle под NFS не работал, не довелось, но идея перспективная, особенно в свете 10G Ethernet.
Очень советую обратить внимание на Best Practices Guide, там все есть и как подключать и как разбивать. В частности про разделение датафайлов, темп и т.д.
В своих системах у меня 3 тома: data, temp, archivelog. Temp не снапшотиться, archivelog советуют ставить snapmirror, но я его пока что на агрегете с sata дисками разместил, места там много и скорость нормальная.
?? самое главное! В 99% создавайте лун с -o noreserve, т.е. без space reserve. ?? к этому ставьте на томе, где лун, autosize.
Тем самым в большинстве случаев не будет душить жаба, что реально у нас база 100гиг, а мы под нее терабайтный лун сделали.
Если много дисков/полок, смысла делать для данных, индексов, темпа и т.д. отдельные агрегейты нет никакого.
Ildarych, серверов много, разнообразных, все по FC, все на одном аггрегате. LUN’ы нарезал с запасом. Первое время после инсталляции системы не был поднят ленточный бэкап и лили на диски. По неопытности - на рабочие луны, а не на отдельные. Ещё момент - частое клонирование баз. ?? прочие операции, когда дисковое пространство занимается на время. Одним словом, в результате имеем изрядно свободного места, про которое Netapp не знает. Проблема только в этом. В плане производительности и защиты данных, тьфу тьфу, вроде всё нормально.
Хочется послушать русскоязычного человека с опытом работы оракла на NFS. А то в анонсах нетаппа больно радостный тон. Либо покупать NFS и тестить самому. А пока что, наверно, придётся мне пересоздать “особо отличившиеся” луны.
Все луны - с noreserve. Про autosize тома я не в курсах. Это что?
Встряну со своей стороны: имейте ввиду, что почти наверняка можно попросить у NetApp демо-лицензию на NFS, чтобы попробовать его практически на вашей реальной системе, и убедиться в его нужности и работоспособности до собственно покупки.
Почти всегда идут навстречу, свяжитесь с поставлявшим вам систему партнером, пусть они свяжутся с представительством.
Это же действует на любую опцию NetApp имеющую лицензию. Не стесняйтесь спрашивать. :)
1. Vol create oradata 100g
2. vol autosize oradata -m 1t -i 10g on
3. lun create -s 1t -t solaris -o noreserve /vol/oradata/lun0
Аутосайз сам расширяет, если кончилось место в томе. Но имейте ввиду, что нормальное расширение, т.е. даже когда что-то пишется работает только с LUN, если на томе сделать NFS шару и поставить авторасширение, то в случае например вы копируете и кончилось место, он ругнется и отвалиться, а потом уже Netapp его расширит и только на инкремент в опции -i.
Т.е. если вы копировали 100Г и нет места, он сто раз будет говорит, что нет места, и 100 раз будет расширяться, поэтому в случае с NFS придеться за местом следить самому.