Проблемы (и решения) Usable Space. Часть 1. Основы.
В ближайшие несколько постов я бы хотел поговорить о некоторых аспектах usable space на системах хранения NetApp. Usable Space на NetApp, а также методы его образования из raw, это также источник бесчисленных спекуляций наших уважаемых конкурентов (в дальнейшем "Н.У.К." ;).
Я отдельно остановлюсь на "говнилках" на эту тему в отдельном посте, а пока давайте разберем фундаментальные основы того, как из Raw Space образуется Usable Space, чтобы подойти к разбору FUD уже теоретически подкованными.
Но начнем издалека.
??так, из чего складывается пространство usable space?
Один из документов NetApp, на который я давал ссылку раньше, так и называется:
Trading Capacity for Data Protection – A Guide to Capacity Overhead on a StoreVault Storage System
Мы платим за надежность хранения raw-байтами, и получаем, в итоге, меньшее по размерам пространство, но с разнообразными "фичами". Это естественный процесс.
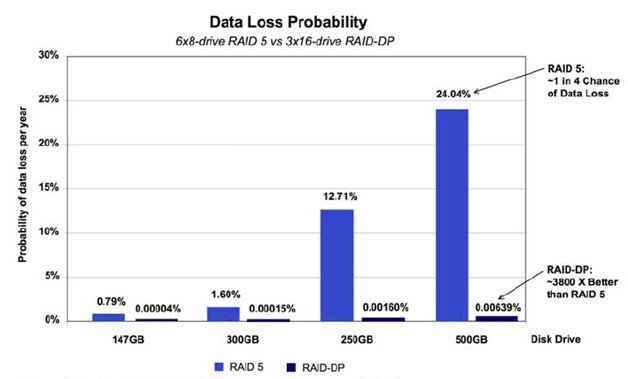
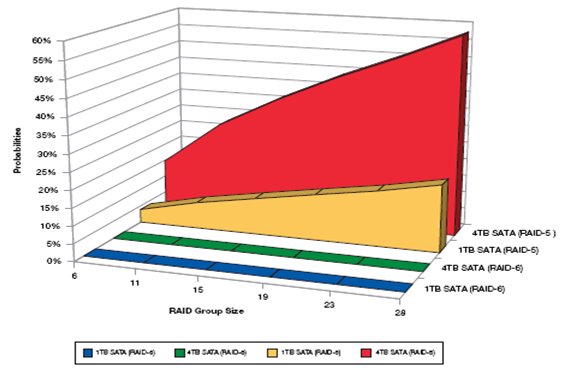
Простейший случай обмена "байтов на надежность" это RAID. Мы платим пространством одного диска (в случае RAID-5), двух (RAID-6), или половиной пространства (RAID-10 AKA RAID 0+1) за надежность и быстродействие.
Поверх RAID мы можем создать журналируемую файловую систему, и получаем "фичу" хранения и обработки "файлов", то есть огранизованных структур данных, со всем им присущим, и, вдобавок, защищаем целостность этих структур. Но, разумеется, партиции, загрузочные области, таблицы размещения файлов, ACL, структуры директориев, и прочее, все это также вычтется в свою очередь из пространства, дав нам взамен вышеописанные возможности, которых не было на простом и тупом raw-диске.
?? так далее, и так далее.
Мы, несомненно теряем на этих процессах мегабайты за мегабайтами, но получаем взамен все новые и новые возможности.
Смешно возражать, что, мол, если бы вы не пользовались на вашей "венде" NTFS-ом, а работали бы прямо в адресации ATA, вы бы могли использовать больше места на диске, которые с ним заняты "непонятно чем".
Уже всем сегодня понятно - "чем".
??з чего же складывается, в свою очередь, usable space на NetApp?
Как вы уже знаете (по крайней мере те, кто давно читает этот блог;), NetApp, как "система хранения данных", довольно "высокоуровнева" по природе, если воспользоваться терминами из области языков программирования. Также как, например, какой-нибудь C# или Java позволяет пишущему полностью абстрагироваться в программе от, например, физической структуры регистров процессора и управления памятью, и заняться более продуктивными вещами, чем вычисления адресов, так и в случае использования пространства хранения на NetApp администратор системы хранения может абстрагироваться от "дисков" и "raw bytes".
Обычно, с повышением "уровня" языка, растет производительность труда программиста, а также становятся доступны многочисленные удобства, хотя апологеты ассемблера и скажут нам (соверщенно справедливо, кстати), что "высокоуровневый программист" и потерял за счет этого ряд возможностей по "тонкой оптимизации". Однако, в окружающей нас жизни, мы, как правило, готовы пожертвовать определенными процентами эффективности программирования ради его удобства, "фич" и скорости разработки.
Подобным путем идет и NetApp.
Он также как и "обычные системы хранения" (тм) использует нижний уровень виртуализации, в виде RAID (RAID это, с точки зрения железа ведь тоже некий "виртуальный девайс"), но начиная с версии своей OS Data ONTAP версии 7 сделан еще один шаг в направлении "высокоуровневой" виртуализации - Aggregates и FlexVol-ы.
Aggregates это "слой дисковой виртуализации", структура (одна или несколько), в которую включены множество имеющихся у системы дисков, своеобразный disk pool, среди которых и распределяется нагрузка ввода-вывода.
Я уже писал раньше о важности такого параметра, как IOPS - Input-Output operations Per Second.
Для отдельного диска величина IOPS сравнительно невелика (в пределах двух, максимум трех сотен для SAS или FC, значительно меньше для SATA). Для того, чтобы увеличить производительность в IOPS, создатели дисковых систем хранения объединяют диски, например с помощью создания RAID-групп. Так, например, RAID-10 ("зеркало" с "чередованием") из 10 дисков будет иметь примерно вдесятеро большую производительность по IOPS, чем отдельный входящий в него диск. Это стало возможным за счет того, что, хотя для внешнего потребителя RAID это "один большой диск", внутри же он состоит из множества меньших, на каждый из которых мы можем писать свою порцию более-менее в параллельном режиме.
Однако бесконечно удлинять RAID тоже нельзя, так как снижается надежность и ухудшаются некоторые другие параметры. Кроме того далеко не всегда для данных, требующих высокой скорости, нужно так много места. А объединив 10 дисков по 300GB в RAID-10 мы получим "диск" размером полтора терабайта (300*10/2) под один только наш "скоростной файл". ?? так для каждой задачи.
Как правило производители "обычных систем хранения"(тм) выходят из положения путем возможности "конкатенации" (сложения A+B+C+D…) сравнительно небольших RAID-групп, и создании на получившемся пространстве так называемых LUN - логических устройств - "дисков".
Как видите, тут тоже своя "виртуализация" имеется.
Большим прорывом в свое время стала разработка уже покойной компанией DEC дисковых систем хранения, в которых появилась возможность объединить все "адресное пространство" жестких дисков, имеющихся в системе, в единый "пул байт", и уже поверх этого пула образовывать "виртуальные RAID" и разделы данных. Наследницы этих систем по сей день производятся компаний HP под названием EVA - Enterprise Virtual Array, и занимают до сих пор довольно значительную долю рынка, хотя нельзя закрывать глаза на тот факт, что системы эти постепенно (и все заметнее) морально устаревают, несмотря даже на столь прорывную и революционную идею в их основе.
Преимуществом объединения всех дисков в "общий пул" является возможность распределить входную нагрузку на все эти диски, работающие параллельно, нарезав на них нужное количество LUN нужных нам размеров, которые, свою очередь, также окажутся размазанными на все наши диски. При этом мы не платим за это "длинным RAID" и всеми его минусами, в виде, например, длительного ребилда и пониженной надежности. То есть, если мы имеем систему с 30 дисками, то, если мы сведем все эти диски в один aggregate, нарежем на нем нужное количество FlexVol, и насоздаем LUN (или будем использовать FlexVol под хранение файлов), то производительность каждого такого FlexVol, и LUN на нем, будет равна: 30*300 IOPS = ~ 9000 IOPS.
Все цифры, разумеется, условные и грубоприближенные, но с сохранением порядка.
??так, начиная с Data ONTAP 7, структура хранения выглядит примерно так:

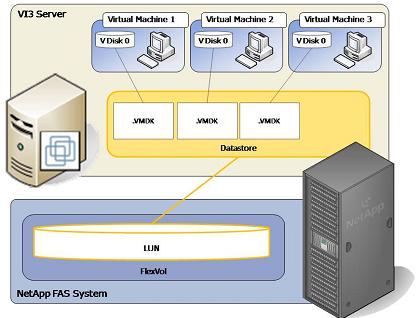
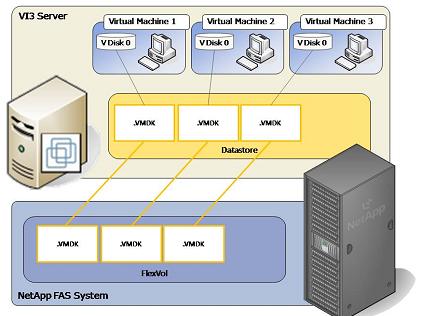
То есть - физические диски, над ними Aggregate, над ними RAID-ы в WAFL, на ней FlexVol-ы, на которых уже, в свою очередь, располагаются LUN-ы или "сетевые папки" NAS.
Каждый из этих уровней немножко отнимает от raw space, и добавляет за это каких-нибудь возможностей.
Продолжение в следующем посте.

![clip_image002[8]](/pics//clip-image0028.gif "clip_image002[8]")
![clip_image002[11]](/pics//clip-image00211.gif "clip_image002[11]")
![clip_image002[13]](/pics//clip-image00213.gif "clip_image002[13]")
![clip_image002[15]](/pics//clip-image00215.gif "clip_image002[15]")
![clip_image002[17]](/pics//clip-image00217.gif "clip_image002[17]")