NFS v4.2: Что нового?
В марте 2012 года, по всей видимости, пройдет окончательную ратификацию “в органах” новая версия протокола NFS – NFSv4.2.
Я уже рассказывал о том, как пару лет назад была выпущена v4.1, главным нововведением которой стал протокол pNFS или Parallel NFS (вопреки модным тенденциям сегодняшнего IT, даже такие значительные изменения, как pNFS, не удостоились v5.0, а считаются всего лишь минорными изменениями версии 4). Про pNFS я тоже уже писал немного, если кому интересно – отсылаю к прошлым постам, если вкратце, то это модификация файловой системы NFS, позволяющей ей работать на параллельном кластере связанных хранилищ, подобно Lustre, Hadoop или GPFS. А сегодня мы собрались для того, чтобы посмотреть на то, что появилось в v4.2. Добавления не настолько глобальные, как в 4.1, но достаточно интересные.
Server-Side Copy (SSC) – это механизм, который позволяет организовывать копирование данных между двумя серверами, не через инициировавшего копирование клиента (чтение на клиента блока с сервера A – запись этого блока на сервер Б, и так далее, пока весь файл не скопирован), а непосредственно. Это чем-то напоминает возможно знакомое кому-нибудь копирование FXP, для двух поддерживающих эту функцию серверов FTP, когда клиент, по командному каналу, указывает для двух серверов, что они должны передать друг-другу файл, после ченго может отключиться, коммуницировать и передавать файл будут два сервера без участия инициировавшего клиента.
Такая возможность значительно снижает нагрузку на канал к клиенту для объемных копирований, например для операций, подобных Storage vMotion, когда содержимое одной VM c одного стораджа, должно быть перенесено на другой сторадж. Теперь это смогут сделать два стораджа, поддерживающие NFS v4.2, самостоятельно, без участия клиента, средствами самого протокола NFS.
Guaranteed Space Reservation – несмотря на то, что thin provisioning для больших инфраструктур это благо с точки зрения эффективности расходования пространства, это большая забота администраторов, в особенности для быстро и непредсказуемо растущих сред. Хотя Thin Provisioning и дает большой выигрыш в расходовании места, за ним “нужен глаз да глаз”. К сожалению до сих пор NFS не предлагал возможности зарезервировать пространство для файлов. Размещение файлов на NFS всегда было thin. Если вы по каким-то своим причинам не хотели использовать thin-модель, то есть занятие места по фактически записанному в файл, а хотели заранее зарезервировать пространство на NFS-хранилище, то у вас не было выбора, а теперь он есть. Guaranteed Space Reservation позволяет, в рамках протокола и файловой системы NFS, создать зарезервированный объем файла, даже не осуществляя в него фактической записи.
Hole-punching. Как вы знаете, одной из наиболее значительных проблем thin provisioning, является проблема “разрастания” thin-файла или раздела (например файла диска виртуальной машины), внутри которого удаляются данные. К сожалению, не имея “арбитра” на уровне приложения, OS, или файловой системы, сторадж не может узнать, вот эти вот блоки, они стерты и больше не нужны, или просто в них давн не пишется, а на самом деле данные в них ценные и их освобождать нельзя. Отчасти эту проблему можно решить, принудительно записывая нули (что, кстати, нынешние файловые системы не делают сами, просто помечая файл у себя как “удаленный”), и считать, что то, где принудительно записаны нули – стерто, и ег можно освободить, и не держать внутри thin-тома, а отдать такое “зануленное” место желающим. Однако общего, стандартного механизма пока не было. А теперь он есть. Начиная с v4.2 при работе по NFS можно обнаруживать такие разрозненные пустые пространства от стертых данных, и освобождать его, “сжимая” файл.
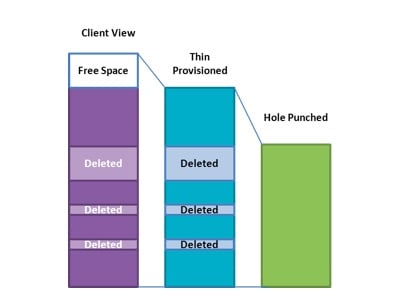
Причем, что немаловажно, такое удаление “дыр из сыра” на уровне стораджа остается полностью прозрачным для использующих его приложений.
Application Data Blocks (ADB) – это механизм для приложений определить некие блоки данных, чтобы затем можно будет заполнять “по шаблону”. Например приложение желает заполнить выделенную область данных определенной сигнатурой. “Классическим образом” вам пришлось бы передать по сети и записать на диск ровно столько блоков, сколько нужно для заполнения нужных областей. Теперь же приложение может определить блок данных как Application Data Block, и заполнить область (с точки зрения приложения) просто указав на этот блок как предопределенный ADB для этой области. Физическое заполнение при этом не происходит, но приложение, обратившись к области данных, получит именно ожидавшееся содержимое.
Aplication I/O Hints – это указание приложением стораджу, средствами протокола, на характер считывания данных с диска. Например: следующие данные будут читаться последовательно, поэтому, пожалуйста, включите на сторадже read ahed. ??ли, наприме: следующие данные мы будем читать несколько раз подряд. Поэтому включите их постоянное хранение в кэше. ??ли данные будут записаны, но читать пока мы их не планируем, поэтому не занимайте место в кэше под них. ?? так далее.
Когда все это богатство ждать? Ратификация стандарта ожидается уже в марте, так как одним из “двигателей” рабочей группы NFS являются специалисты NetApp и EMC, то в этих продуктах новые возможности будут реализованы в скором времени после ратификации стандарта. Насколько будут востребованы новые фичи на стороне клиента – ну тут решать стороне клиента, то есть, в конечном счете – вам.





